I recently found some old Fighting Fantasy gamebooks I remembered from my childhood. One in particular stood out as having seemed next to impossible. I never finished it. I had vague recollections of infinite loops and dead ends, of getting fed up of playing by the rules and yet still not managing to find the way through when I bookmarked pages and backtracked from untimely deaths.
For those unfamiliar with the series, these were like Choose Your Own Adventure books, but in addition to your choices, you also had to roll dice and keep track of your health and inventory throughout the book. You could die from your wounds due to bad luck as much as bad decisions, although generally with sufficiently good choices you could minimize the likelihood of such an outcome.
I've found some accounts that describe the correct path through this book (e.g. solution 1, solution 2) but I wanted to do something a bit more thorough, so I decided to diagram the entire book and have a look at what made it quite so nasty. I woefully underestimated how much work this would be, but it's done now, for better or worse. I also did a crude Monte Carlo simulation to try to figure out how hard the book is even when you know exactly what to do.


Overview

I've split the book into lettered chunks of closely related pages. Sections A through M cover your escape from the dungeon. Sections N through W cover your search for the necromancer Zharradan Marr. There's a bottleneck around the middle, but both before and after there are sections with a lot of branching.
Throughout the book, there are a number of items or abilities that you need to find to be able to make progress later on. In some cases (e.g. the elven dust), it just asks you if you've got the item and if so to turn to page X. But with most of them, the book will tell you some number or operation when you get them, possibly with instructions about when to apply it to find a new page to turn to. In this way, it's not always obvious when or if you were missing an important item. The items that you must not miss in order to complete the book (marked in gold on the diagrams) are the pendant, the club, the ability to decipher codes, the ring of holy blessing, the ability to enter the netherworld, the elven dust, the assistance of Grog, the sculliweed and the ring of truth.
During the first half of the book, there are many different ways through, but there's essentially one long correct path, and a large number of shortcuts that skip out different sections of this path, missing the opportunity to obtain essential items. There are also some dead-ends and short optional sections.
Random wandering


During the first part of the book, everything is determined by dice rolls. You have no free-will. It is entirely possible, though relatively unlikely, to die before you get to make a single decision. You get four chances to get onto the path of success, but if you get the wrong path every time you end up in a dead-end section headed for one of a variety of certain deaths. Apart from disorienting you, this section hampers an honest player from powering through with the same decisions every time they play - you need to repeat the rolls every time and might have to take a different path. Given the improbability of heading down the doomed path, you also get a nagging sense of having missed something, since until you've died down that path a lot you're never sure if there was a way through that you might have missed.
You can see that I've coloured in deadly pages as black, and I've also shaded in dark grey those pages that inevitably lead to death. Page 408 marks your certain doom as you fall onto the unlucky path that will inevitably see you die on page 99, 14 or 260.
In fact, there's really nothing of terribly great importance in these first sections. It's not until you reach section C and your choices open up that you can start screwing up of your own accord...
The power to choose

Section C branches rapidly, and provides many ways to fail. There's no backtracking to this point, so if you miss the magic pendant on page 306 (coloured gold) you will certainly die eventually. The bracelets and the coins might seem useful, but they are distractions from the pendant. Those paths which necessarily miss a vital page are coloured light grey. You can't win once you find yourself on one of these pages, but they're not as bad as the dark grey pages, because they do return to the main path, and while you can't finish the book, you may still learn something useful along these paths. In contrast, the dark grey pages are cul-de-sacs, and at best all they offer is an entertaining death.
From here, branches lead to sections D, F, G, H, I and J, but as there's no backtracking, leaving to any section other than D will miss out important discoveries and prevent you from finishing.

The pendant is one of several mechanisms that lets you turn to pages that are not listed as options. When you see the key-text "You cannot see a thing" you can subtract 20 from the current page number to find a secret. You need to use it here in section D to gain the crystal club, another essential item that is needed much later on. You get the option to use it in combat by turning to another page, but this is a trap - it destroys the club which you need towards the end of the book.

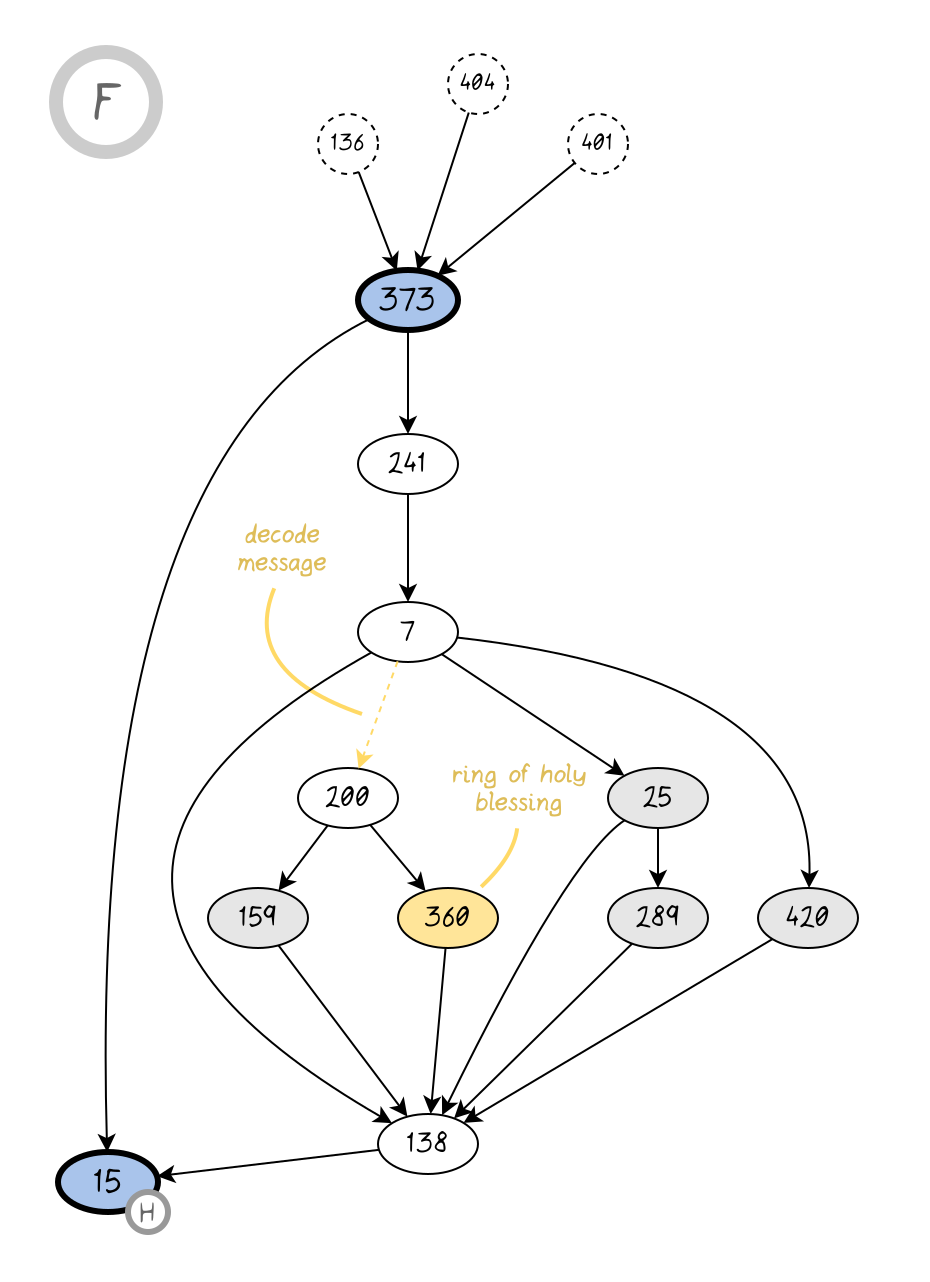
Section E yields the secret to the codes found throughout the book. This too is absolutely necessary, since some of the coded passages contain instructions to tell you to turn to another page. The code is slightly frustrating - it explains how to encode text, but the operation is slightly lossy, and you need to make some guesses in order to reverse it correctly in all cases. There are also some optional items to obtain here, but the sack seems to be useless, since the conditions to use its ability never seem to come up. It would make sense if it allowed you to collect all three kinds of plant in the swamp instead of picking just one, but there's no allowance for this in the text. The rhino's message unlocks some sections later on that can only be accessed on a doomed path, so it's a bit of a red herring. The breastplate seems like the best optional item here, but I'm not certain whether it's worth it. It makes you better at fighting but worse as skill checks. There's only one skill check on the critical path, but failing it spells doom.

Section G misses the ring in section F, but it does introduce the use of the pendant in a hard-to-miss way. There are a bunch of interlinked pages that you can wander back and forth between, one of which has the trigger-words for the pendant, and one of which kills you. If you don't have the pendant you're stuck, but if you do hopefully you'll notice the opportunity to use it as you wander around.




Section K contains the notorious misprint. The trigger-words for the pendant are missing from page 213. However, the layout here is very similar to section G and the dead-end is pretty suspicious, so it's perhaps not wholly impossible to guess what you're supposed to do here.


Section L introduces a pretty elaborate warren of dead-ends for you if you have missed the secret code or the ring of holy blessing. It will take you quite a few deaths in the mines, or fighting an endless loop of chaos warriors to discover that there is no way through here. I think the endless loop is quite cruel, and it isn't the only time the book does this to you!
Section M similarly has a large number of ways to fail, although all lead to the same end, unless you are lucky enough to be killed by the guard. This has the peculiar feature of a page that ends with "Unless you wish to try battering the door down (turn to 128), you have reached the end of your journey." This sounds like an optional death, but really it's just there to confirm that yes, this is an infinite loop, and your choices are to slowly batter yourself to death in a futile attempt to break down the door, or to put the book down and walk away.
Outside the dungeon

In section N, you are finally free from the dungeon. But rather cruelly, one of the paths here takes you right back into the dungeon, back to section K, only this time you no longer have your pendant so you are trapped with no way to escape.

Section O introduces the friendly half-orc Grog (assuming you manage to find and rescue him) with a nice little system where whenever a page number ends in "7", you can subtract a number and Grog will say or do something to help before you turn back to the page you were on.


In section Q, poor Grog meets his demise. You actually turn to a page that kills you (hence I've shaded it black), but since it ends in a "7", you can turn to another page and continue. Grog, sadly, does not get to continue. Hopefully you were paying attention when Rosalina told you that sculliweed has blue stems, otherwise you'll be taking a short and miserable trip to Dree.


Much like the end of the dungeon, if you miss the trick in section S, by not having the ring, not remembering to use it or simply not asking the right questions, you'll end up in a large dead-end section, exploring magic pools and getting lost in the forest.

The Galleykeep
Section T is the finale. Some of the critical requirements here were from far, far back at the beginning of the book, so you might get here with no idea of how to proceed. Again, most of the paths here require knowledge of secrets from earlier on, so you may not even realise that you're missing something. There's another death loop here - if you're unlucky enough to find the undead physician, you'll have to keep fighting him over and over until you die.

There are a few ways to end up in Dree, and not much to do there other than die! If you read the introductory material at the start of the book you might know not to trust anyone offering you potions there, but the knowledge won't help you much.

The training camp is another red herring. It's possible to get out of it alive with the help of your rhino friend, but you won't get far beyond it, because you won't have the ring of truth.
Simulation
I hacked up a rudimentary simulator in Python to run through the critical route. It's not optimal, because it's pretty hard to know when best to use the option to "test your luck" during combat. I also haven't experimented with trying to kill the rhino-man to steal his breastplate, which trades off skill for attack strength. But nevertheless, here's the result of running 10,000 trials:
You were mind-controlled by a wizard. 2920 You win! 2089 You were killed by dark elves. 1260 You drowned in the Bilgewater. 986 Killed by <THIEF, skill=8, stamina=6>, <WARRIOR, skill=7, stamina=7> 682 Killed by <First BLOOD ORC, skill=7, stamina=7>, <Second BLOOD ORC, skill=8, stamina=7> 440 Killed by <WARRIOR, skill=8, stamina=9> 343 You beat yourself against a door. 295 Killed by <CLAWBEAST, skill=9, stamina=14> 214 Killed by <FIGHTER IN LEATHER ARMOUR, skill=7, stamina=8> 159 Killed by <First FLESH-FEEDER, skill=6, stamina=6>, <Third FLESH-FEEDER, skill=6, stamina=6>, <Second FLESH-FEEDER, skill=6, stamina=7> 158 Killed by <STRONGARM, skill=7, stamina=8> 128 You could not control the ophidiotaur. 83 Killed by <ARMOURED KNIGHT, skill=8, stamina=9> 80 You were eaten by the Galleykeep crew. 72 Killed by <MANIC BEAST, skill=7, stamina=8> 59 A knight stabbed you in the back. 21 Killed by <HOBBIT, skill=5, stamina=6> 7 Killed by <Second BRIGAND, skill=8, stamina=7>, <First BRIGAND, skill=8, stamina=9> 3 Killed by <TOADMAN, skill=9, stamina=9> 1
So it seems to work out that, if you know the path, and play by the rules, you have around a 20% chance to survive to the end. Perhaps it's a little higher if you make better decisions. That wizard right at the start is really deadly! I'm amused that the hobbit managed to kill us 0.07% of the time, and the door is really quite dangerous, killing us 2.95% of the time. I'm curious why the toadman gets so few kills, but I suspect that it's because very weak characters have already been weeded out, and you get healed shortly before the encounter. Overall this isn't quite as hard as I had thought - the difficulty of the book largely comes from all the secrets that necessitate an extremely thorough search of every corner of the book.
If you want to mess around with the code, feel free. I make no guarantees that it's actually correct! It was a quick, fun and not in any way rigorous. I've put it in a github repo along with the drawio files for the diagrams.
Here's what the description of the book looks like - all the options have been stripped away, so apart from the random bits at the start, it's a straight path all the way through.
book = {
'1':Seq(
Compare('1d6', '<=', 3, then=Goto('205')),
Compare('1d6', '<=', 2, then=Goto('205')),
Compare('1d6', '<=', 1, then=Goto('205')),
Fight([Character('CLAWBEAST', 9, 14)]),
Compare('1d6', '<=', 4, then=AddStat('stamina', 2)),
Compare('1d6', '<=', 3,
then=Die('You were killed by dark elves.')),
Goto('205'),
),
'205':Seq(
Fight([Character('HOBBIT', 5, 6)], aggressive_luck=True),
Compare('combat-duration', '<=', 3,
then=TestStat('luck', on_fail=
Die('You were mind-controlled by a wizard.')),
otherwise=Compare('1d6', '<=', 4, then=
Die('You were mind-controlled by a wizard.'))
),
AddStat('stamina', -2, 'A knight stabbed you in the back.'),
Fight([Character('ARMOURED KNIGHT', 8, 9)]),
RestoreStat('stamina'),
Compare('1d6', '<=', 2, then=AddStat('skill', -1)),
Compare('1d6', '>=', 4, then=AddStat('stamina', -2)),
Fight([
Character('First FLESH-FEEDER', 6, 6),
Character('Third FLESH-FEEDER', 6, 6),
Character('Second FLESH-FEEDER', 6, 7),
]),
AddStat('luck', 2),
Fight([Character('STRONGARM', 7, 8)]),
Fight([
Character('THIEF', 8, 6),
Character('WARRIOR', 7, 7),
]),
AddStat('luck', 1),
TestStat('luck', on_fail=
Die('You drowned in the Bilgewater.')),
Fight([Character('WARRIOR', 8, 9)]),
Fight([Character('FIGHTER IN LEATHER ARMOUR', 7, 8)]),
AddStat('luck', 1),
Fight([
Character('First BLOOD ORC', 7, 7),
Character('Second BLOOD ORC', 8, 7),
]),
AddStat('luck', 2),
TestStat('luck', on_fail=
Die('You drowned in the Bilgewater.')),
AddStat('stamina', -1, 'You beat yourself against a door.'),
Fight([
Character('MANIC BEAST', 7, 8, manic=True),
]),
AddStat('stamina', 4),
RestoreStat('stamina'),
AddStat('stamina', 8),
AddStat('luck', 2),
RestoreStat('skill'),
Fight([Character('VILLAGER', 7, 8)]),
AddStat('luck', 2),
AddStat('stamina', 4),
Fight([Character('TOADMAN', 9, 9)]),
RestoreStat('luck'),
RestoreStat('luck'),
RestoreStat('stamina'),
TestStat('skill', on_fail=
Die('You could not control the ophidiotaur.')),
Fight([
Character('Second BRIGAND', 8, 7),
Character('First BRIGAND', 8, 9),
]),
TestStat('luck', on_fail=TestStat('luck', on_fail=
Die('You were eaten by the Galleykeep crew.'))),
Fight([
Character('Second GOBLIN', 5, 5),
Character('First GOBLIN', 6, 5),
]),
Win()
),
}
Conclusion
I think this book is better appreciated as a masterpiece of cruelty than as a game. It's very cleverly constructed, but I'm not sure how much you can really take that in just from playing it. I don't remember enjoying it nearly as much as other such books when I was a child. It's just overwhelming, and requires a great deal of attention and note-taking. I think the variety from random outcomes can keep things interesting for a while, but I can't imagine it still being fun by the time you've finally pieced together everything that you have to do. I wonder how many people ever finished it without cheating. I certainly was not one of them.
PS - Draw.io is really great! I started drawing the diagrams in Inkscape, but it was too slow and its connectors weren't as easy to use. Draw.io did a generally good job, although it's a bit rubbish at exporting. I had a lot of hassle because I'm using a custom font, and most of the export options end up trashing the text in one way or another.











